최근에 들어서 신문이나 잡지에서 는 인공지능에 대한 기사가 하루라도 빠지지 않고 관심을 끌고 있다. 인공지능이 인간을 지배한다는 이야기도 서슴없이 나오고 있지만, 사실 지금으로서 는 인공지능을 여러 방면에서 활용되면서 각 사용자에게 좀 더 맞는 서비스를 제공하고 편의와 효율성을 제공하는 시점이라고 보면 될 것 같다.
인공지능을 활용하는 분야 중의 하나가 의료정보를 활용한 인공지능의 개발이다. 질병 진단에 이미 활용이 되고 있다 는 사실은 누구나 알고 있는 이야기이다. 진단 분야 외에도 치료, 의약개발, 사전예측 분야, 사후 관리 분야 등에 활용되고 있다. 그런데 인공지능은 결국 Big Data에 기반을 두고 분석과 논리를 통해서 답을 구하는 방법이라 Big Data 없이는 제대로 인공지능을 활용할 수 없게 된다. 여기서 활용되는 Big Data에는 의료 정보뿐만 아니라 개인정보도 포함할 수 있다.
인류는 제2차 세계대전이 진행되는 동안 영국의 말렌 튜링이라는 천제적인 수학자를 통해서 독일의 암호해독을 위한 기계를 만들어 낸다. 이 기계를 튜링머신이라고도 불렀는데 지금의 컴퓨터 구조를 정립한 최초의 기계이자 현대 인공지능 (Artificia lIntelligence (A.I.))의 시초라고 할 수 있다. 이 튜링머신으로 인해서 인류 는 2차 세계대전의 종전을 2년 정도 앞당길 수 있었고 1,400만명 이상의 생명을 구할 수 있었다 . AI라는 용어는 1956년에 존 매카시 교수가 다트머스 대학에서 열린 대회를 통해 처음으로 사용했는데 인간처럼 생각하고 문제를 풀 수 있는 알고리즘을 연구하기 시작한 것이다.
그 이후로 컴퓨터, 인터넷의 발달로 인해서 AI는 1950년대부터 1980년대까지 전성기를 맞았고 잠시 그발전이 주춤하였으나 1990년대를 거쳐 2000년대 들어서 신경망 (Neural network)을 기반으로 하는 딥러닝(Deep Learning) 기법이 발달하게 되었고, 인터넷 발전으로 인해 데이터가 폭발적으로 늘어나게 되자 현대
사회는 빅데이터의 시대를 맞게 되었다.
AI의 판단은 기초적인 데이터를 기반으로 하고 있기 때문에 대부분 Big Data에 기반을 두고 있다. 따라서, AI를 훈련시키는 데이터의 질에 따라 AI가 다른 답을 낼 수도 있다. 결국 좋은 데이터로 훈련을 받은 AI은 좋은 답을 낼 것이고 질이 떨어지는 데이터로 훈련을 받 은 AI는 덜 떨어진 답을 내는 것이다. 현재 AI는 일상생활에 이미 들어와 많이 활용이 되고 있다. 패턴 분석을 통한 마케팅, 번역, 음성인식, AI 비서, 음악서비스, 질병관리, 자율주행, 언어교육, 보안 및 해킹방지, 투자 관리, 의료 등에 활용되고 있다. 그렇다면 의료에 활용되고 있는 AI의 법적인 측면을 어떠한 것이 있을지 집중적으로 논의해보고자 한다.
의료와 관련된 정보는 개인정보 측면에서 보면 개인정보를, 의료법 측면에서는 보건의료정보 (“의료정보”)를
포함하고 있다고 볼 수 있다. 따라서 어떤 정보를 가지고있고 어떻게 활용하느냐에 따라서 취해야 하는 보호방법이 달라질 수도 있다. 개인정보보호법에 보면 건강에 대한 정보는 민감정보에 포함된다. 또한 같은 법 시행령에 보면 유전정보도 민감정보에 들어간다고 되어 있다.
개인정보 측면에서 이러한 민감정보는 원칙적으로 그 처리가 금지되어 있으나, 정보주체의 동의가 있거나 다른 법률에서 명시적으로 민감정보 처리를 요구하거나 허용하는 경우 (해석상 요구되는 경우 포함)는 가능하도록 되어 있다. 개인정보의 입장에서 각 국의 의료데이터를 활용하는 방법은 각기 다르다.
먼저 2018년 5월 25일부터 효력을 발생하게 된 유럽의 General Data Protection Regulation (“GDPR”) 에서는 여러 조항에서 건강에 대한 데이터나 유전자에 관한 정보에 대한 규제를 두고 있다. 유전자 정보, 건강에 관한 정보 등은 개인정보의 특정범주로 규정하고 의료 진단이나 치료, 또는 해당국의 법에 의한 서비스나
사회복지 제도에 필요한 경우에 해당국의 권위있는 기관에서 인정하는 자격을 갖춘 전문가의 판단에 의해
처리할 수 있도록 되어 있다. 또한 GDPR의 제11조에 신원확인을 필요로 하지 않는 개인정보에 대해 규정하고 있는데 의료정보를 빅데이터에 활용할 수 있는 조항으로 매우 중요한 조항이다.
정보처리자가 신원확인을 요구하지 않거나 더 이상 요구하지 않아도 되는 경우 정보처리자의 판단에 의해 정보주체를 식별할 수 없다는 것을 증명할 수 있는 경우는 GDPR상에서의 권리가 적용되지 않는다. 따라서, GDPR상에서는 의료정보를 활용할 수 있는 길을 마련해 놓았는데, 전문가의 판단에 의하거나 비식별화가 된 정보는 활용할 수 있다.
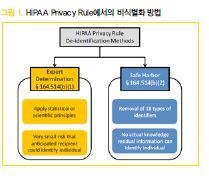
미국에는 Health Insurance Portability and Accountability Act (“HIPAA”) 에서 의료정보에 대해 다루고 있는데, 개인의 건강정보를 보호할 목적으로 별도의 HIPAA Privacy Rule을 따로 제정해서 운영하고 있다. 그 HIPAA Privacy Rule에서도 건강정보의 유용성에 대해 인식을 하고 있고 §164.502(d)에서 규정하고 있는 바와같이 비식별화 표준을 따르거나 전문가의 판단에 의해 비식별화가 된 정보는 활용을 할 수 있도록 하였다.
비식별화 표준에 의하면 전문가의 판단에 따라 결정할 수 있다. 일반적으로 받아들여지고 있는 통계나 과
학적인 원리나 방법으로 경험이나 지식이 있는 자로 규정을 하고 있어서 전문적 학위나 증명서를 취득할 것을 요구하지 는 않는다. 전문가에 의해 정보를 받은 주체가 개인을 식별할 가능성이 매우 낮을 것으로 판단이 되는 경우에 활용을 할 수 있도록 되어 있어서 자율에 맡기고 있다. 전문가는 (1) 복제성, (2) 데이터소스의 가용성, (3) 구별 가능성, (4) 접근 위험성 등을 고려해서 결정을 한다.
다른 하나의 방법은 18개의 식별자를 제거한 피난처방식 (Safe Harbor method)을 취하면 활용 가능하다. 18
개의 식별자는 (1) 이름, (2) 주소 (작은 지역을 규정할 수 있는 주소 식별자), (3) 생년월일, 퇴원일 등 개인에게 직접적으로 관련된 날짜에 관한 정보, (4) 전화번호, (5) 팩스번호, (6) 이메일 주소, (7) 사회보장제도 번호, (8) 의료 기록번호, (9) 건강보험 수혜자 번호, (10) 계좌번호, (11) 자격취득번호 또는 라인센스 번호, (12) 자동차 식별 번호와 일련번호, (13) 장비 식별번호 및 일련번호, (14) URL 정보, (15) IP 주소, (16) 생체정보, (17) 얼굴 전면사진, (18) 기타 고유한 식별번호이다. 위의 18개의 식별자가 제거된 정보는 비식별화 된 정보로 간주를 하고 빅데이터로 활용할 수 있다. 따라서 의료정보를 빅테이터로 만들어서 AI에 여러 방면에서 활용할 수 있는 것이다.
한국에서의 의료정보 활용은 생명윤리법에 의해 많이 제한되어 있다. 의료정보는 연구용으로는 사용할 수
있게 규정이 되어 있다. 생명윤리법에서는 개인식별정보를 연구대상자의 성명, 주민등록번호 등 개인을 식별 할 수 있는 정보로 규정하고 있고 개인정보는 개인식별 정보, 유전정보 또는 건강에 관한 정보 등 개인에 관한 정보를 말한다 고 규정이 되어 있어 개인정보보호법에서의 개인정보 정의보다 좀더 넓게 정의가 되어 있다.
생명윤리법에서는 몇 가지 예외를 제외하고는 연구대상자의 서면동의가 있어야 개인정보 (건강에 관한 정보
포함)를 활용할 수 있다. 다만 개인정보를 제3자에게 제공하는 경우는 익명화를 해야 한다. 다만 연구대상자의 동의를 받는 것이 현실적으로 불가능하거나 연구의 타당성에 심각하게 영향을 미친다고 판단을 하는 경우와 연구대상자의 동의 거부를 추정할만한 사유가 없고 동의를 면제하여도 연구대상자에게 미치는 위험이 극히 낮은 경우는 서면동의를 받지 않아도 된다. 따라서 일부 예외적인 경우를 제외하고는 연구대상자의 동의 없이는 연구용 활용뿐만 아니라 일체의 활용이 금지되어 있다.
그러나 연구대상자의 정보는 비식별화를 통하여서 가능할 수 있다. 다만 비식별화를 한 뒤에 다른 정보를결합해서 개인을 식별할 수 있게 되지 않아야 한다. 일단 비식별화가 된 정보는 개인정보로 취급이 안되므로 의료 분야에서의 활용이 가능하다. 의료정보의 비식별화에 대해서는 “개인정보 비식별 조치 가이드라인”에따르면 되는데 표1에 나와 있는 바와 같이 여러가지로 비식별화를 할 수 있다.
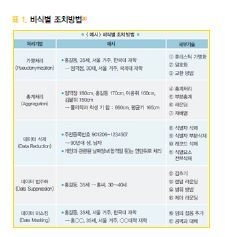
비식별화는 (1) 특정데이터가 한 개인과 대응 (Singleout); (2) 특정데이터와 특정 개인이 연결 (Linkability);
(3) 특정개인을 추론 (Inference) 하게 되는 연관성을 없애는 방법인데, 익명처리 (Anonymization)는 위 세가지를 모두 제거하는 것이고, 가명처리(Pseudonymization)는 개인과 대응은 할 수 있도록 하지만 연결과 추론은 제거하는 것을 말한다.
한국은 다른 나라와는 달리 국민의료정보에 대한 건강정보가 국민건강보험공단과 건강보험심사평가원에
보험이 적용되는 모든 사람들에 대한 모든 건 강정보 자료가 있다고 봐도 과언이 아니다. 이 의료정보들이 활용될 수 있다면 무한한 가치를 갖게 된다. 그러나 현재는 연구용으로 활용을 한다고 하더라고 연구대상자에 대해 서면동의를 얻어야 활용이 가능한데, 현재 각 기관에서 가지고 있는 의료정보에 대해 모든 사람의 동의를 얻는다는 것은 현실적으로 거의 불가능하다.
따라서 의료정보를 활용할 수 있는 방법은 의료정보의 비식별화로 활용할 수 있는 방법이 효율적일 수 밖에
없다. 이에 따라 국민건강보험 공유서비스에서는 진료내역정보, 의약품처방정보, 건강검진정보를 비식별화 해서 일반에게 공개하여 활용을 하도록 하고 있다.
이제까지 개인정보 측면에서의 의료정보 활용을 간단히 알아 보았는데, 의료정보를 개인정보 측면에서 비
식별화 등의 방법으로 활용을 한다고 하더라고 다른 법률적 이슈는 아직 많이 남아 있다. 정보의 소유권이 누구에게 있는가 하는 문제, AI를 활용해서 의료행위의 판단을 했는데 혹시 환자에게 손해가 발생해다면 그 책임을 누구에게 물을 것인가 하는 문제, AI는 결국 소프트웨어 인데 제조물 책임을 물을 수 있는가 하는 문제 등등 아직 해결해야 할 숙제들이 많이 남아 있다. 법의 발전이 기술의 발전을 앞서 갈 수는 없겠지만, 기술적 발달의 혜택을 누리기 위해서는 이러한 숙제들을 시급히 해결되어야 할 것 같다.
")